
안녕하세요. 개발하는 정주입니다.
오늘은 "Array(배열)"을 정리하였습니다.
배열이란?
배열은 대부분의 프로그래밍 언어에 포함된 선형 자료 구조인데요.
동일한 데이터 타입(연관된 데이터)을 하나의 변수에 순서대로 나열한 뒤 메모리에 연속으로 저장해 만든 자료 구조입니다.
데이터를 순서대로 나열한다는 점과 메모리에 연속으로 저장이 된다는 점이 배열의 포인트입니다.
배열은 동일한 데이터 타입을 저장하기 때문에 다른 데이터 타입을 담을 수는 없습니다.
Int Array에 Double이나 String을 넣지 못하는 것이 예시입니다.
그런데 Swift에서는 Any 타입을 이용해 여러 타입을 하나의 배열에 담을 수도 있죠?
저도 배열을 조사하며 이것에 대해 궁금해져서 찾아본 결과!
Any 타입의 배열은 Any 타입의 동일한 데이터가 나열된 것이므로 배열의 규칙에 위배되지 않는다고 합니다.
(https://forums.swift.org/t/how-does-swift-know-the-address-of-an-element-in-an-array-of-any/45415?_x_tr_sl=auto&_x_tr_tl=ko&_x_tr_hl=ko)
배열 구성
배열은 index, value, element로 구성되어 있습니다.
- index : 배열에서 순서를 나타내는 부분입니다. Swift, C/C++, Java 등에서 index는 0부터 시작합니다.
- value : 배열에서 값에 해당하는 부분입니다.
- element : value와 index를 합친 요소입니다.
배열 시간복잡도(Big-O)
배열의 시간복잡도는 아래와 같습니다.
O(1)
- 특정 Index에 있는 원소를 참조하는 연산
- 특정 Index의 원소의 값을 변경하는 연산
- 배열의 가장 끝에 원소를 추가하는 연산
- 배열의 가장 끝의 원소를 삭제하는 연산
배열은 Index를 이용해 O(1)만으로 요소에 접근할 수 있습니다.
배열의 원소 추가, 삭제를 무조건 O(n)라고 착각할 수 있지만 마지막 원소를 추가, 삭제하는 연산은 O(1)의 시간 복잡도를 가집니다.
그 이유는 바로 아래에서 알려드리겠습니다.
O(n)
- 특정 원소를 찾는 연산 ex. 배열에 2가 있는지 검색
- 임의의 위치에 원소를 추가하는 연산
- 임의의 위치에 원소를 삭제하는 연산
임의의 위치에 원소를 추가, 삭제하는 연산은 O(n) 시간 복잡도를 가집니다.
왜냐하면 배열은 "연속적으로" 원소가 와야하기 때문입니다.
삽입 및 삭제된 요소로부터 이후에 있는 요소들을 모두 이동 시켜야 합니다.
삽입 연산이라면 삽입되는 index 이후의 요소들을 모두 뒤로 한 칸씩 밀어야 합니다.
반대로 삭제 연산은 삭제한 index 이후의 요소들을 모두 앞으로 한 칸씩 당겨야 합니다.
이 연산들은 최악의 경우 총 n번이 반복될 수 있기 때문에 O(n)의 시간복잡도를 가지는 것입니다.
특정 원소를 찾는 연산은 배열 원소 값을 하나씩 체크해야 하므로 최악의 경우 n번 반복될 수 있습니다.
따라서 O(n)의 시간복잡도를 가집니다.
배열 장단점
배열의 장점
- Index를 이용한 빠른 접근이 가능하다.
- 간단하고 사용하기 쉽다.
배열의 단점
- 정적 크기 배열은 정적 메모리 때문에 크기를 변경할 수 없다.
- 중간 위치의 원소 삽입, 삭제가 느리다.
배열이 유리한 경우
배열은 하나하나 적는 것이 불가능할 정도로 너무 많은 곳에서 사용되고 있고 많은 자료구조에서 활용되고 있습니다.
따라서 언제 배열을 쓰면 좋을지 알아보겠습니다.
- 같은 데이터 타입을 순차적으로 저장하고 싶은 경우
- 배열 중간에 삽입/삭제 연산이 적은 경우
- Index를 이용한 빠른 참조가 필요한 경우
- 다차원 데이터를 다루는 경우
Swift에서 알아보자
Swift에서 배열을 검증(?)해보는 시간을 가졌습니다. 정말 메모리에 순차적으로 저장이 될지..!
먼저 말씀드리면 예상치 못한 결과가 나왔고 정확한 이유를 찾지 못하였습니다.
참고만 해주시고 이유를 아시는 분은 꼭 좀 알려주시면 감사하겠습니다 ㅠㅠ
일단 Swift는 언어 자체가 안전성을 1순위로 하기 때문에 포인터의 접근을 비권장합니다.
하지만 지금 상황처럼 포인터를 확인해야 할 때를 위한 메서드를 지원하는데요.
Swift에서 포인터를 다루는 메서드는 모두 Unsafe를 붙여 안전하지 않다는 것을 암시합니다.
제가 사용한 메서드는 그 중 하나인 withUnsafePointer()입니다.
Apple Developer Documentation
developer.apple.com
Code
일단 코드입니다.
import Foundation
var a1: String = "1", a2: String = "22", a3: String = "333"
var arr: [String] = ["1", "22", "333"]
var arr2: [[String]] = [["1", "2", "3"], ["11", "22", "33"], ["111", "222", "333"]]
print("size: \(type(of: a1)) / \(MemoryLayout.size(ofValue: a1))")
withUnsafePointer(to: &a1) { print("a1 addr: \($0)") }
withUnsafePointer(to: &a2) { print("a2 addr: \($0)") }
withUnsafePointer(to: &a3) { print("a3 addr: \($0)") }
print("------1------")
for i in 0..<arr.count {
withUnsafePointer(to: &arr[i]) {
print("addr: \($0) / value: \($0.pointee)")
}
}
print("------2------")
arr.append("4444")
for i in 0..<arr.count {
withUnsafePointer(to: &arr[i]) {
print("addr: \($0) / value: \($0.pointee)")
}
}
print("------3------")
arr.removeFirst()
for i in 0..<arr.count {
withUnsafePointer(to: &arr[i]) {
print("addr: \($0) / value: \($0.pointee)")
}
}
print("------4------")
for i in 0..<arr2.count {
for j in 0..<arr2[i].count {
withUnsafePointer(to: &(arr2[i][j])) {
print("addr2: \($0) / value: \($0.pointee)")
}
}
}a1, a2, a3은 단일 변수로 생성하고 arr는 1차원 배열, arr2는 2차원 배열로 생성했습니다.
size가 16byte인 String으로 테스트 하였습니다. Int는 8Byte로 출력되던데 계산하기가... ㅎㅎ
단일 변수
먼저 a1, a2, a3의 결과부터 볼까요??
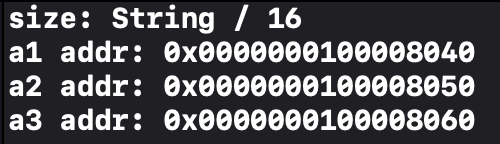
사실 저는 C처럼 중구난방의 메모리 주소가 출력될 것이라 예상했지만 너무 깔끔하고 연속적으로 나와서 당황했습니다.
이는 실제로 연속적으로 저장된 것은 아닙니다.
현재는 a1, a2, a3을 연속으로 생성해줬습니다.
a3의 선언을 arr2 이후에 한 결과입니다.
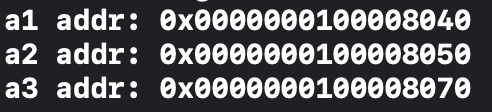
결과가 달라진 것을 볼 수 있습니다. 너무 깔끔한 주소에 당황했지만 아무튼 연속으로 저장이 안 된다는 것을 알 수 있습니다.
1차원 배열
이제 1차원 배열을 볼까요?

각 원소들의 메모리 주소가 연속적이라는 것을 볼 수 있습니다.
배열은 예상대로 나와줘서 감사했습니다.
2차원 배열
마지막으로 2차원 배열 차례입니다.
C언어를 기준으로 2차원 배열도 말만 2차원이지 한 줄로 이어진 배열입니다.
다만 index를 계산을 2차원적으로 하겠다는 것이지요.
따라서 주소를 출력하면 연속적으로 나와야 합니다.

하지만 결과를 보니 주소가 연속적이지 않았습니다.
하지만 규칙이 없는 것은 아니었는데요. 다음 원소(배열)로 갈 때 3개 원소 크기만큼의 갭이 있었습니다.
그래서 첫 번째 배열의 원소의 개수를 5개로 늘려보았습니다.
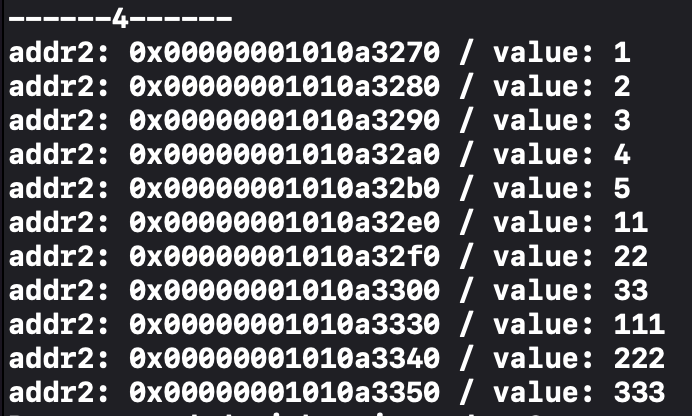
그래도 3개 원소 크기만큼의 갭이 있네요. 그렇다면 1차원 배열의 개수에 영향을 받는건가? 싶었습니다.
그래서 배열 원소를 하나 더 추가하여 테스트를 해보았습니다.
헷갈리실 거 같아 지금의 arr2 상태를 알려드립니다.
var arr2: [[String]] = [["1", "2", "3"], ["11", "22", "33"], ["111", "222", "333"], ["1111", "2222"]]

그래도 똑같이 48byte만큼의 갭이 있네요!
저는 이유를 잘 모르겠더라고요... ㅠㅠ
마무리가 얼렁뚱땅 된 것 같아서 아쉽네요. 그래도 굉장한 것을 알게 된 것 같아요.
사실 배열은 너무 익숙하고 기초적인 자료구조라 다룰까 말까 고민을 했는데 다루길 잘 한 것 같습니다.
잘못된 점이 있다면 댓글로 알려주시면 감사하겠습니다.
감사합니다.